Alibaba launches Qwen 3.5 small model series with sub-1B edge options
Written by Joseph Nordqvist/March 2, 2026 at 2:57 PM UTC
4 min readAlibaba's Qwen team has released four new small language models — Qwen3.5-0.8B, 2B, 4B, and 9B — alongside their base model counterparts, extending the Qwen3.5 architecture to compact, resource-efficient deployments.
The release, announced March 2 on X, positions the series as a practical option for edge devices, lightweight agents, and industrial research. All four models share the same foundation as the larger Qwen3.5 family: native multimodal capability, an improved architecture, and training with scaled reinforcement learning.
The launch of the Qwen 3.5 Small Model Series adds to a growing ecosystem of models designed for local deployment, where cost, latency, and data privacy are priorities.
What Was Released
Qwen3.5-0.8B and 2B — Designed for speed and minimal compute, with edge hardware deployments as the primary use case.
Qwen3.5-4B — Described by the team as "a surprisingly strong multimodal base for lightweight agents," indicating competitive capability at a size that can run on consumer hardware.
Qwen3.5-9B — The largest of the series, benchmarked against models significantly bigger than itself.
Base model weights for all four sizes are also being released, which the team said is intended to better support "research, experimentation, and real-world industrial innovation."
Dual Operating Modes: The models officially support two states:
Non-Thinking: Optimized for speed, general chat, and standard visual tasks.
Thinking: Engages a Chain-of-Thought reasoning process to solve complex logic, math, and coding problems.
Dense Architecture: While the larger 35B+ versions of Qwen 3.5 use Mixture-of-Experts (MoE), the small series (0.8B–9B) are dense. Every parameter is active for every response, maximizing reasoning depth for their physical footprint.
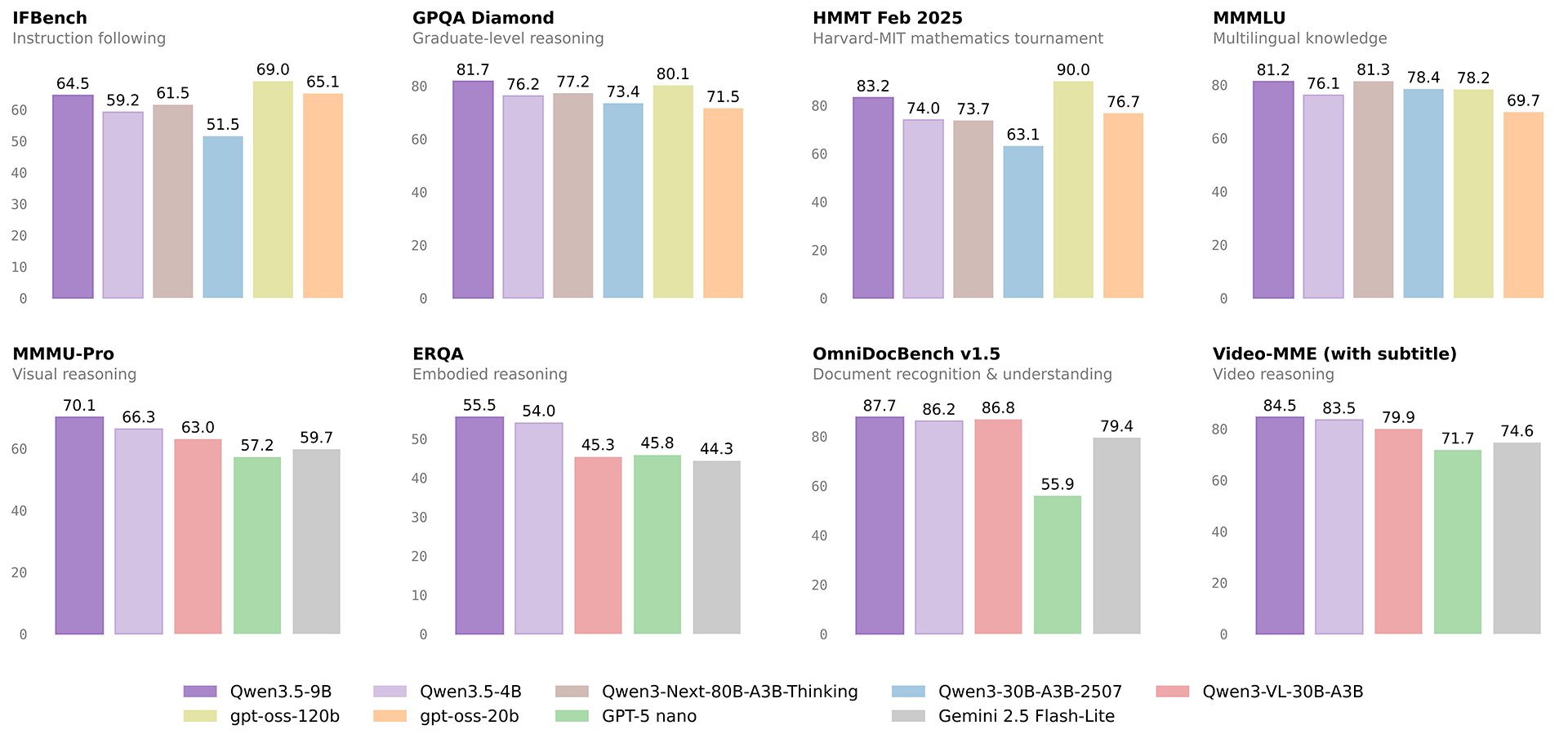
Benchmark Performance
According to benchmarks self-reported by Alibaba alongside the release, the Qwen3.5-9B shows particularly strong results in instruction following (91.5 on IFEval) and long-context tasks (63.0 on AA-LCR), outperforming several larger models in those categories. On knowledge benchmarks like MMLU-Pro (82.5) and MMLU-Redux (91.1), the 9B also posts competitive scores relative to the GPT-OSS-120B baseline included in the comparison.
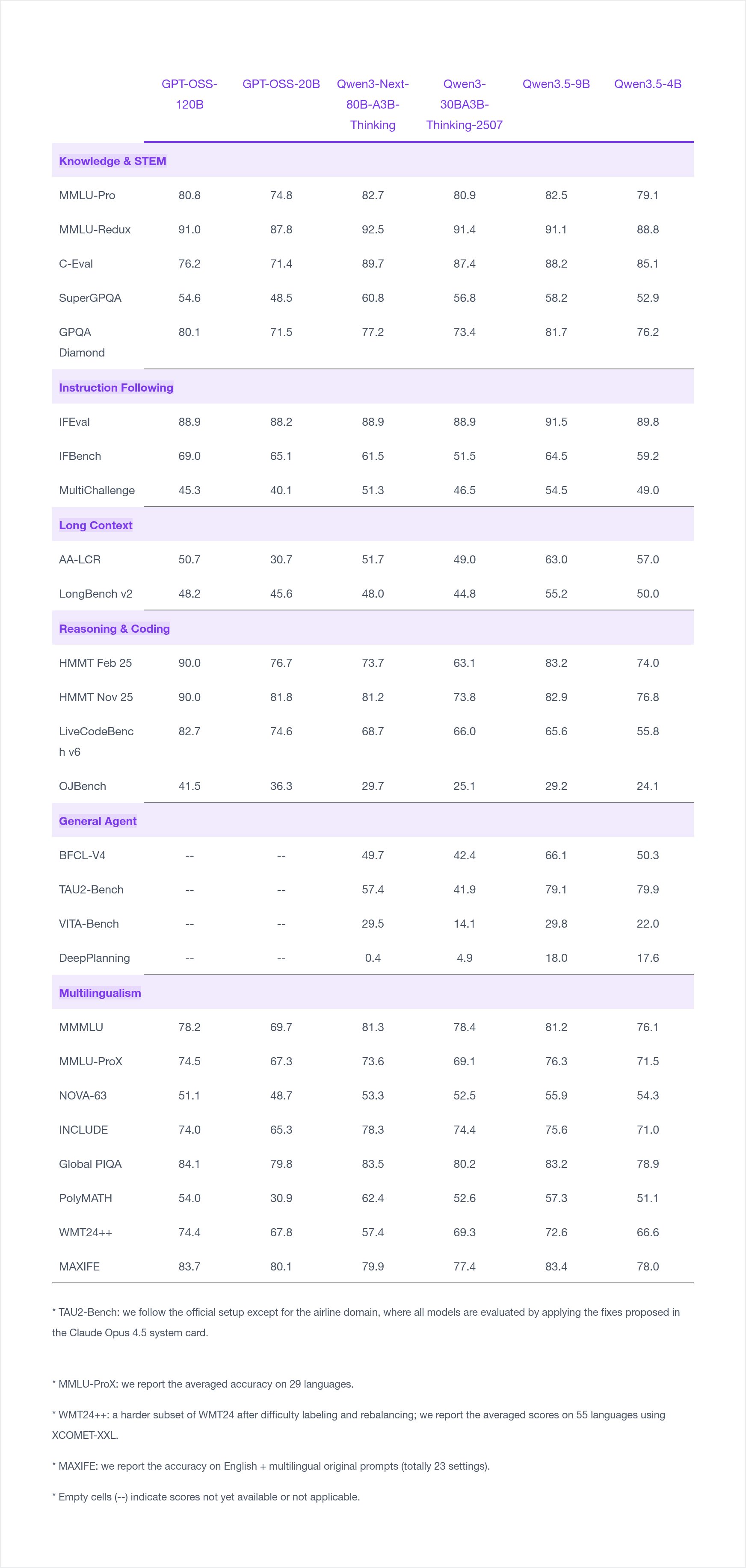
The Qwen3.5-4B demonstrates solid multilingual performance across 29-language and 55-language evaluations, suggesting it may be viable for international deployment scenarios despite its compact size.
On reasoning and coding tasks, both the 4B and 9B lag behind the larger GPT-OSS-120B on HMMT benchmarks — an expected gap given the parameter difference — but remain competitive on LiveCodeBench v6.
General agent benchmarks (BFCL-V4, TAU2-Bench, VITA-Bench, DeepPlanning) were only reported for the Qwen3.5 models in this comparison, not for GPT-OSS variants, limiting direct comparison on agentic tasks.
Context
The release continues a pattern of frontier labs publishing small model series that punch above their weight class, particularly for deployment scenarios where cost, latency, and local execution matter more than absolute benchmark rank. Alibaba has made Qwen3.5 models available via Hugging Face and ModelScope.
AI News Home covers AI industry developments with primary source verification. Benchmark data is self-reported by Alibaba and has not been independently verified.
Written by
Joseph Nordqvist
Joseph founded AI News Home in 2026. He studied marketing and later completed a postgraduate program in AI and machine learning (business applications) at UT Austin’s McCombs School of Business. He is now pursuing an MSc in Computer Science at the University of York.
View all articles →This article was written by the AI News Home editorial team with the assistance of AI-powered research and drafting tools. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
Was this useful?