Anthropic releases Claude Opus 4.6 with 1M context window
Written by Joseph Nordqvist/February 5, 2026 at 8:38 PM UTC
12 min read
Anthropic announced Claude Opus 4.6, the latest version of its highest-end Opus model.[1]
The company says the model is stronger at coding, planning, and long-running agentic tasks, and introduces a 1 million token context window in beta.
The release also includes updates to Claude Code and the Claude API, aimed at helping teams run longer workflows with more automation and less manual coordination. Anthropic says Opus 4.6 also powers improved performance within Cowork, its agentic work tool launched in January.
Context and background
Anthropic’s Claude lineup is typically presented in three sizes: Opus (largest), Sonnet (mid), and Haiku (smallest). Opus releases tend to target enterprise use cases such as large codebases, complex reasoning tasks, and multi-step work that requires tool use, document handling, and extended context.
In parallel, the AI tools market has been shifting toward “agentic” workflows, where a model does not just answer questions, but runs multi-step processes such as searching, drafting, iterating, calling tools, and coordinating subtasks over time. Anthropic positions Opus 4.6 as an upgrade specifically for those longer workflows.
Key details
What was released
Anthropic says Claude Opus 4.6 improves on Opus 4.5 in several developer-focused areas:
More careful planning and stronger performance on long-running tasks.
Better reliability in larger codebases, plus stronger code review and debugging behavior.
Better long-context retrieval, intended to reduce performance degradation in lengthy conversations.
It is available on claude.ai, through Anthropic’s API, and through “major cloud platforms,” according to the company.
The 1 million token context window
The biggest platform-level change is that Opus 4.6 includes a 1 million token context window (beta) for the first time in the Opus line.
In practical terms, a larger context window matters when teams want a model to:
Read and reference very large documents or multiple documents at once.
Work across a large codebase without constantly re-feeding key files.
Maintain continuity in long workflows such as debugging, refactoring, or research and synthesis.
A large context window does not automatically guarantee strong long-context performance. For that, the model has to reliably retrieve what matters from the earlier text, and not “drift” as the conversation grows. Anthropic explicitly addresses that failure mode and claims Opus 4.6 shows less drift than its predecessor on long-context tasks.
Benchmarks Anthropic highlighted
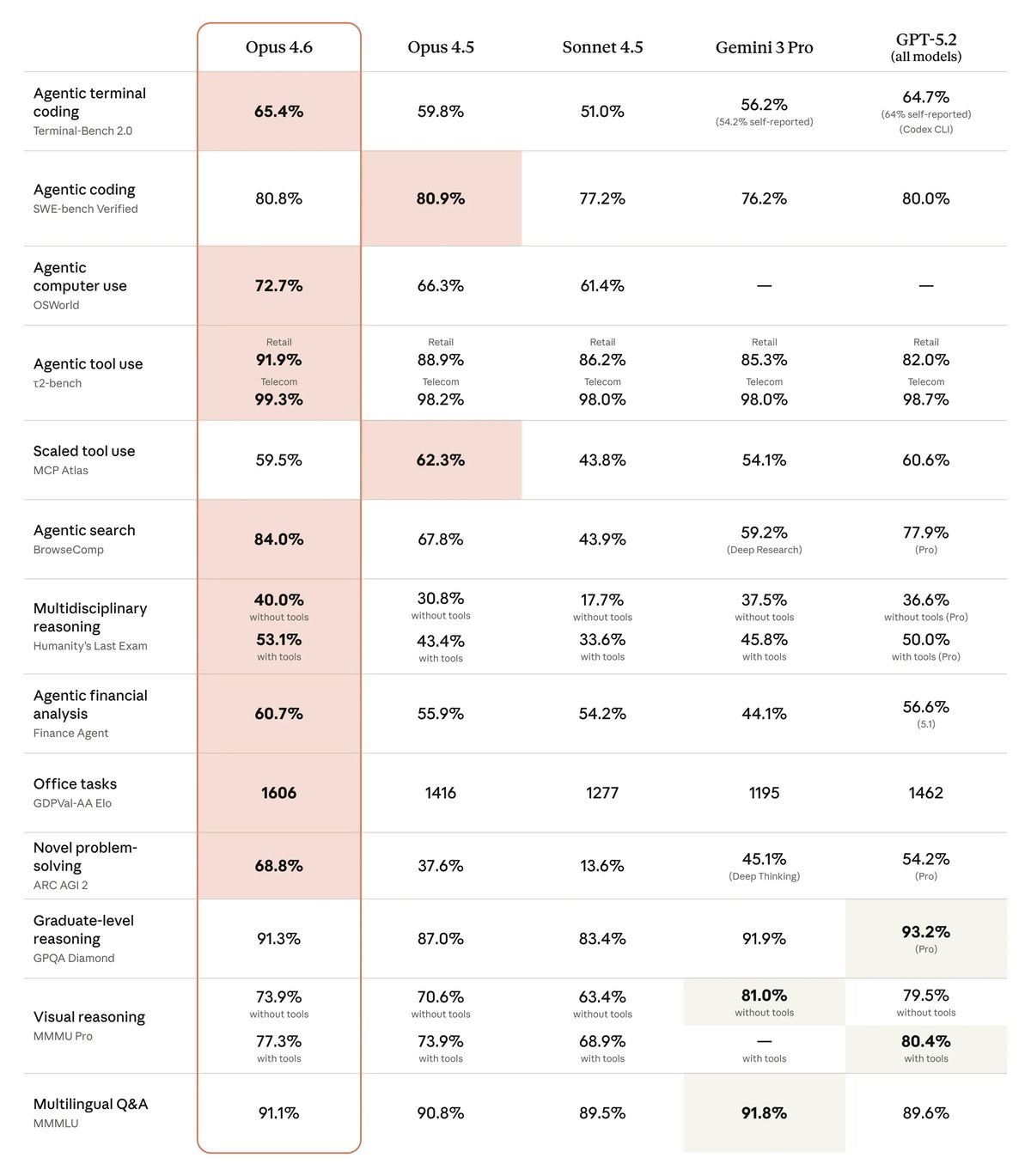
Anthropic’s announcement points to several evaluations where it claims Opus 4.6 is state of the art, including:
Terminal-Bench 2.0 (agentic terminal coding): 65.4%, up from 59.8% for Opus 4.5.
Humanity’s Last Exam (multidisciplinary reasoning): 53.1% with tools, up from 43.4%.
BrowseComp (finding difficult information online): 84.0%, up from 67.8%.
GDPval-AA (knowledge-work tasks across professional domains): Elo of 1606, where Anthropic claims Opus 4.6 beats OpenAI’s GPT-5.2 by about 144 Elo points, corresponding to winning about 70% of the time.
ARC AGI 2 (novel problem-solving): 68.8%, nearly double Opus 4.5’s 37.6%. This benchmark tests problems that are easy for humans but hard for AI systems, making it a qualitatively different signal than the enterprise-focused evaluations above.
Where benchmarks did not improve
Not every benchmark moved in Opus 4.6’s favor. Anthropic’s own table shows small regressions on two coding-related evaluations:
SWE-bench Verified (agentic coding): 80.8%, slightly below Opus 4.5’s 80.9%. Anthropic notes in its footnotes that a “prompt modification” raises this to 81.42%, but the headline number is a marginal regression.
MCP Atlas (scaled tool use): 59.5%, down from Opus 4.5’s 62.3%. Anthropic notes that at a different effort setting (high instead of max), Opus 4.6 reaches 62.7%, but the comparison is not apples-to-apples.
These regressions are worth noting because they show the upgrade is not uniformly positive even by the vendor’s own numbers, and because SWE-bench Verified is one of the most widely watched coding evaluations in the industry.
More broadly, many of these results are reported by the vendor, and some depend on specific tool setups, harnesses, and sampling choices.
Anthropic's own caveat on benchmark precision
Anthropic's engineering team published a post shortly after the Opus 4.6 launch noting that infrastructure configuration alone, such as how much memory or CPU a test container receives, can shift agentic coding benchmark scores by up to 6 percentage points.[2]
The team recommends that leaderboard differences below 3 points "deserve skepticism" until evaluation setups are documented and matched.
By that standard, some of Opus 4.6's claimed leads (including its less-than-1-point edge over GPT-5.2 on Terminal-Bench 2.0) fall within the range that infrastructure noise could explain.
Long-context retrieval and “context rot”
Anthropic claims Opus 4.6 addresses “context rot,” a shorthand for models getting worse at retrieving and using earlier information as token counts rise.
The company highlights the 8-needle 1M variant of MRCR v2 as a key data point: Opus 4.6 scores 76%, compared to just 18.5% for Sonnet 4.5.
The 8-needle 1M variant of MRCR v2 is a long-context retrieval test that goes beyond simply finding a buried fact. The model is given a synthetic conversation roughly 1,500 pages long (1 million tokens) in which the same request — for example, "write a poem about birds" — appears eight times, each time producing a different but similar response. The model is then asked to return a specific one, such as the third. The difficulty is not just finding the information, but distinguishing between eight very similar responses based on where they appeared.[3]
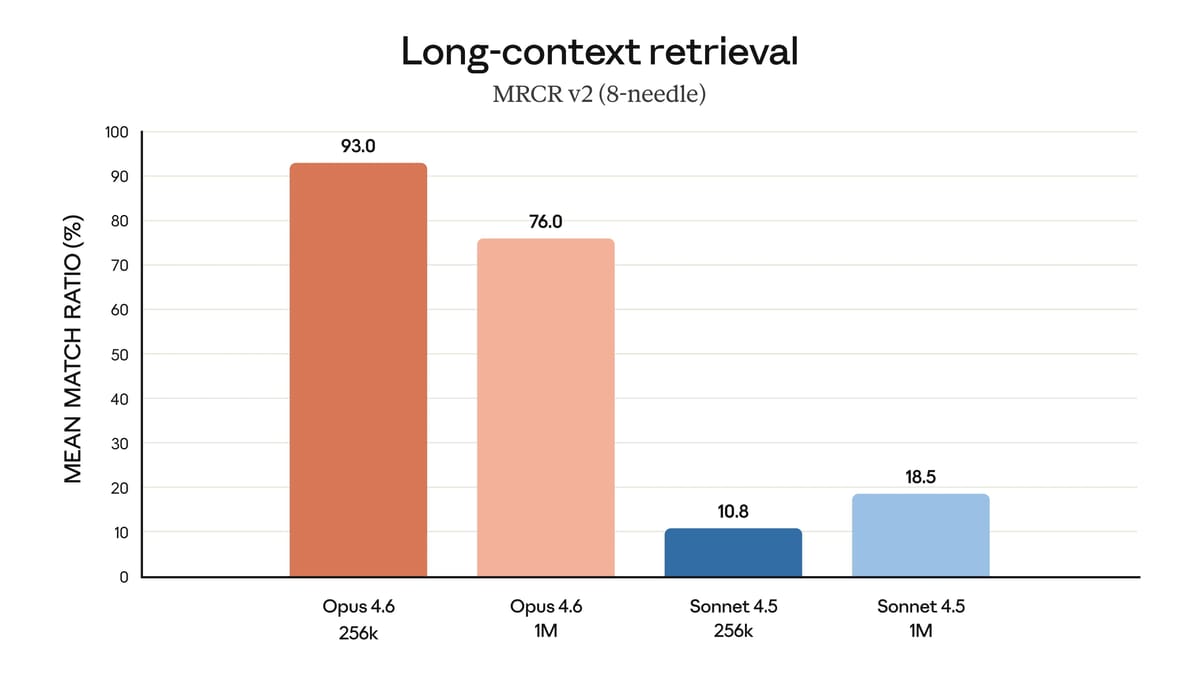
Anthropic describes this as “a qualitative shift in how much context a model can actually use while maintaining peak performance.”
This matters a lot for enterprise work because long sessions are common in real workflows. A model that can accept very long context but cannot reliably retrieve key details is often worse than a smaller-context model with stronger retrieval, because it creates a false sense of continuity.
Safety and alignment
Anthropic says Opus 4.6 matches its predecessor on alignment metrics while achieving the lowest over-refusal rate of any recent Claude model, meaning it is less likely to refuse benign queries.
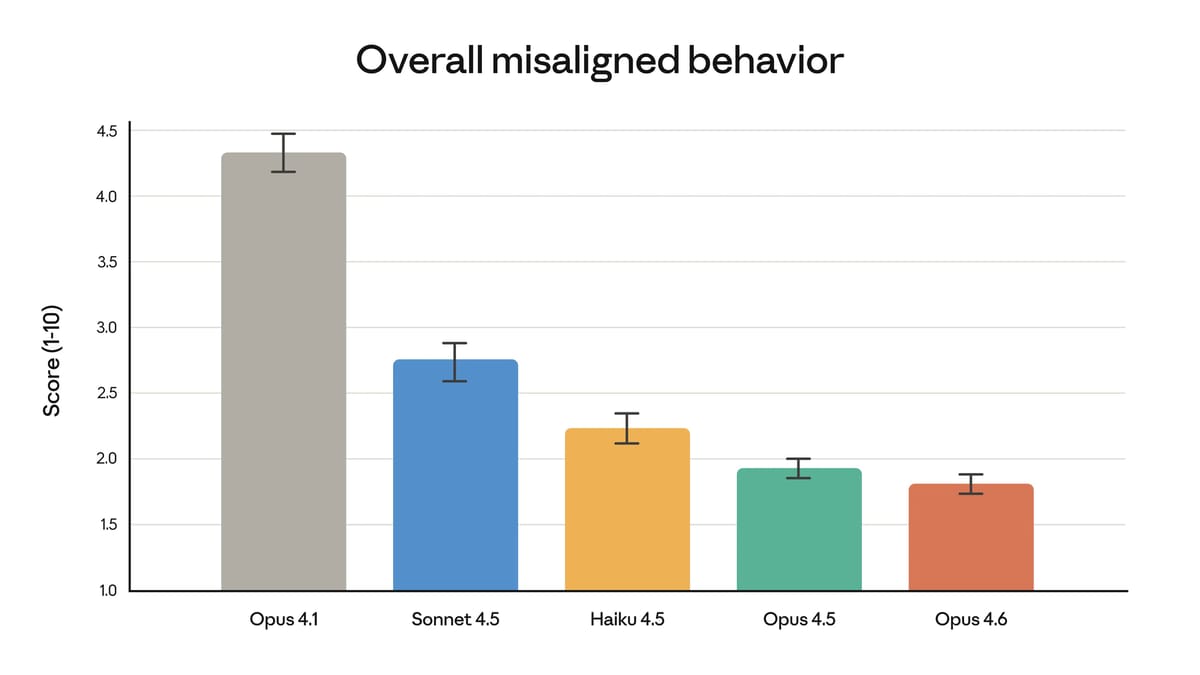
The company says this is the most comprehensive set of safety evaluations it has run on any model, including new tests for user wellbeing, more complex refusal evaluations, and updated probes for surreptitious harmful behavior.
The cybersecurity dimension deserves particular attention. Anthropic reports that Opus 4.6 shows “enhanced cybersecurity abilities” and has developed six new cybersecurity probes to track potential misuse.
That capability cuts both ways: it is potentially valuable for defenders, but also raises the stakes for misuse. Anthropic says it is “accelerating the cyberdefensive uses of the model” and may institute real-time intervention to block abuse, while acknowledging this “will create friction for legitimate research.”
Claude Code: “agent teams” (research preview)
Anthropic says Claude Code now supports “agent teams” as a research preview, where multiple agents can work in parallel on a task and coordinate autonomously.
The intended use case Anthropic describes is work that splits into read-heavy, semi-independent chunks such as:
Codebase reviews.
Parallel investigations of different subsystems.
Frontend/backend separation when the interfaces are clear.
This is part of a broader market pattern: coding tools increasingly resemble “work orchestration” products, not just chatbots. The user is effectively managing a system that can spawn subtasks, keep state, and coordinate partial results.
Agent teams in practice: building a C compiler autonomously
Alongside the Opus 4.6 announcement, Anthropic published a detailed case study of agent teams in action. Nicholas Carlini, a researcher on Anthropic's Safeguards team, tasked 16 parallel Claude agents with building a Rust-based C compiler from scratch, then largely stepped away.[4]
Over nearly 2,000 Claude Code sessions and roughly $20,000 in API costs (2 billion input tokens, 140 million output tokens), the agents produced a 100,000-line compiler capable of building a bootable Linux 6.9 kernel on x86, ARM, and RISC-V, as well as projects like FFmpeg, SQLite, PostgreSQL, and Redis. The agents coordinated through a simple locking mechanism on a shared git repository, with no orchestration agent managing high-level goals.
The post is candid about what did not work. The generated code is less efficient than GCC even with all optimizations disabled. The compiler is not a drop-in replacement for a production tool. New features frequently broke existing functionality. And the model was unable to implement a 16-bit x86 code generator needed for one phase of the Linux boot process, falling back to GCC instead.
Carlini frames the project as a capability stress test rather than a product demonstration, writing: "I did not expect this to be anywhere near possible so early in 2026." He also flags a concern that applies beyond this experiment: when code is produced autonomously at scale, the usual assumption that a developer has personally verified what ships no longer holds.
API changes for longer-running workflows
Anthropic’s announcement includes several API-side features aimed at agentic tasks:
Adaptive thinking, where the model can decide when deeper reasoning is useful rather than requiring a strict on/off switch.
Effort levels (low/medium/high/max) to trade off intelligence, speed, and cost.
Context compaction (beta) that summarizes older context as the conversation approaches a threshold, intended to extend agent runtimes without hitting limits.
128k output tokens, enabling much longer single outputs, such as large code changes or long documents.
The combination of compaction, effort controls, and large output limits is essentially an attempt to make long workflows more stable and predictable. Instead of a “single prompt, single response” model, this supports multi-step sessions where a system needs to keep working without collapsing under context size.
Office integrations: Excel upgrades and PowerPoint preview
Anthropic says it has upgraded Claude in Excel and is releasing Claude in PowerPoint as a research preview for Max, Team, and Enterprise plan customers.
The PowerPoint integration allows Claude to read existing layouts, fonts, and slide masters, and generate or edit slides that preserve those design elements. Previously, users could ask Claude to create a PowerPoint file, but the file had to be transferred into PowerPoint for editing. The new integration works directly inside the application.
The announcement frames this as part of a broader push to treat professional documents, spreadsheets, and presentations as first-class outputs for Claude.
Pricing and availability
Anthropic says Opus 4.6 base pricing remains $5 per million input tokens and $25 per million output tokens. Premium pricing of $10/$37.50 per million tokens applies for prompts exceeding 200,000 tokens when using the 1 million context window.
It also describes an option for US-only inference at 1.1× token pricing for workloads that must run in the United States.
Why this matters
Claude Opus 4.6 is a product update, but it is also a signal about where model competition is concentrating.
Long-running work is becoming the main differentiator. Short answers and basic code generation are no longer enough to stand out. Vendors are now competing on whether models can hold up across hours of work, messy inputs, tool use, and partial failures.
Context length is shifting from a headline number to an operational capability. A 1 million token window is only useful if retrieval stays reliable and the system can prevent drift. Anthropic is explicitly aiming at that operational reliability problem, not just the size of the window.
Multi-agent workflows are moving into mainstream developer tooling. “Agent teams” are a concrete step toward parallelized coding workflows. If the coordination works well, the practical benefit is not just speed, but the ability to keep multiple lines of investigation active without losing track of decisions and evidence.
Benchmarks are being used to describe job-shaped capabilities—but the details matter. Terminal tasks, browsing for hard-to-find information, and professional knowledge work are closer to enterprise outcomes than older, purely academic tests. At the same time, the exact setup behind each benchmark matters. Opus 4.6’s own results show regressions on SWE-bench Verified and MCP Atlas even as it leads on most other evaluations, and footnotes reveal that some headline numbers depend on specific harnesses, effort settings, or prompt modifications. Readers should treat vendor claims as directional unless independently reproduced.
Cybersecurity capabilities are becoming a dual-use frontier. A model that can autonomously find hundreds of zero-day vulnerabilities is a powerful tool for defenders and a potential accelerant for attackers. How Anthropic and the broader industry manage this tension—through detection, access controls, and real-time intervention—will be an important story to watch beyond this single release.
Outlook
It is still unclear precisely how much Opus 4.6’s claimed gains will translate into everyday developer productivity across typical environments, especially when tool availability, security controls, and enterprise data constraints vary widely.
It is also unclear how quickly multi-agent features such as “agent teams” will move from research previews into stable enterprise deployments, since parallel agents raise practical questions about observability, audit trails, and consistent outcomes.
The competitive context is worth noting: OpenAI released its Codex desktop application just three days before this launch.[5] It also released GPT-5.3-Codex, a new agentic coding model, mere hours after Opus 4.6 launched.[6]
The broader software market has seen significant disruption. Bloomberg reported that Anthropic’s Cowork automation tool (which first launched in January) helped trigger a roughly $285 billion selloff across software, financial services, and asset management stocks.[7] Whether these fears are well-calibrated or overblown remains an open question, but the pace of releases from both Anthropic and its competitors suggests the pressure will continue to intensify.
Editorial Transparency
This article was produced with the assistance of AI tools as part of our editorial workflow. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
- 2.
Quantifying infrastructure noise in agentic coding evals — Gian Segato, Engineering at Anthropic, February 5, 2026
- 3.
- 4.
- 5.
- 6.
- 7.
Anthropic AI Tool Sparks Selloff From Software to Broader Market — Carmen Reinicke, Joe Easton, and Henry Ren, Bloomberg, February 3, 2026
Was this useful?
More in Products
View all- Alibaba launches Qwen 3.5 small model series with sub-1B edge optionsMarch 2, 2026
- Claude Code now remembers what it learns between sessionsFebruary 27, 2026
- Google launches Nano Banana 2, bringing pro-level image generation to its Flash modelFebruary 26, 2026
- Anthropic launches Remote Control for Claude Code, enabling mobile accessFebruary 25, 2026
Related stories
OpenAI upgrades ChatGPT deep research with GPT-5.2 and new controls
February 10, 2026
Models"Fast mode" for Claude Opus 4.6, 2.5x speed at 6x the price
A new "fast mode" for Claude Opus delivers up to 2.5 times higher output token generation speed at a significant premium: six times the standard.
February 8, 2026
ProductsOpenAI drops GPT-5.3-Codex right after Anthropic's Opus 4.6
February 6, 2026
ProductsOpenAI releases standalone Codex app for macOS
OpenAI released a dedicated macOS application for Codex, its AI-powered coding assistant. The app is designed to serve as a "command center" that makes it easy for software developers to manage multiple AI agents at once.
February 2, 2026