Cohere Transcribe, the most accurate open-source speech recognition model currently available
Written by Joseph Nordqvist/March 27, 2026 at 6:36 AM UTC
5 min read
Cohere's first speech recognition model tops the Open ASR Leaderboard as well as our own independent benchmark of four providers.
Cohere released Transcribe on March 26, a 2-billion-parameter automatic speech recognition (ASR) model that the company says is the most accurate open-source option currently available. The model is open-weights under Apache 2.0 and available on HuggingFace, with a free rate-limited API and managed deployment through Cohere's Model Vault infrastructure.
The release marks Cohere's first entry into speech recognition. The company, best known for its enterprise-focused text generation and retrieval models, is positioning Transcribe as the foundation for a broader speech intelligence capability within North, its AI agent orchestration platform.
Transcribe uses a conformer-based encoder-decoder architecture, where a large Conformer encoder processes log-Mel spectrograms from audio input and a lightweight Transformer decoder generates text tokens. At 2B parameters, it sits in the mid-range of the current ASR field.
The model supports 14 languages: English, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Chinese, Japanese, Korean, Vietnamese, and Arabic. It requires the language to be specified upfront, as it does not perform automatic language detection.
Cohere reports a 5.42% average word error rate (WER) on the HuggingFace Open ASR Leaderboard, which the company says places it first among both open- and closed-source dedicated ASR models. The leaderboard evaluates models across eight standardized datasets including multi-speaker meeting recordings (AMI), earnings calls (Earnings 22), and accented speech (Voxpopuli).
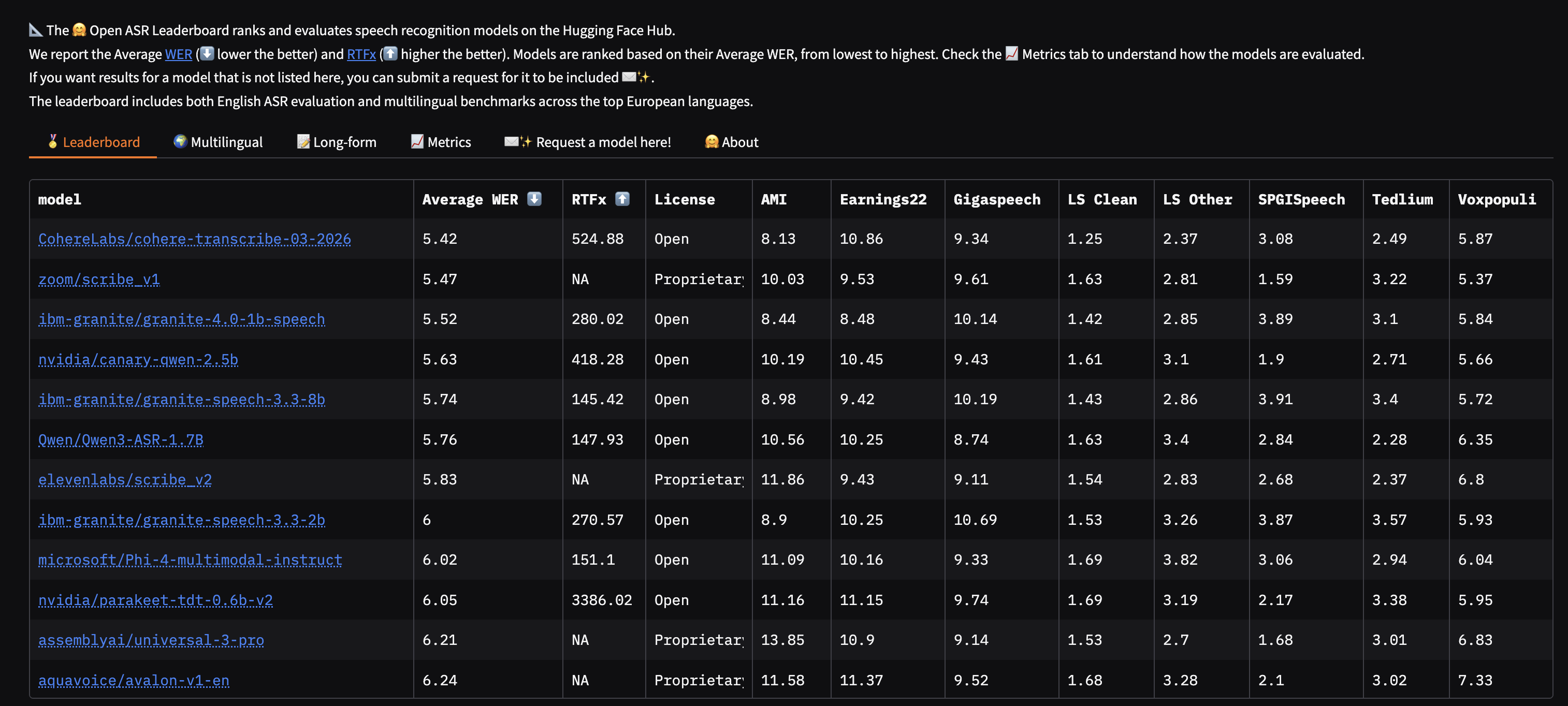
The margins on that leaderboard are thin. Zoom Scribe v1 sits at 5.47%, IBM Granite 4.0 1B Speech at 5.52%, and NVIDIA Canary Qwen 2.5B at 5.63%. OpenAI's Whisper Large v3, the most widely used ASR model, comes in at 7.44%.
We also ran our own independent benchmark to see just how Cohere’s new model stands.
Our benchmark: four providers, 320 API calls
To evaluate Transcribe against established commercial alternatives, we benchmarked four speech-to-text APIs across eight audio samples with 10 runs each, totaling 320 API calls. The four providers were Cohere Transcribe, OpenAI Whisper, Deepgram Nova-2, and AssemblyAI.
The test set was designed to cover conditions that matter in production: clean baseline speech, telephone-quality audio at 8kHz, synthetically generated noise at 15 dB and 5 dB SNR (using pink noise at verified levels), Indian-accented and French-accented English from the IDEA Dialect Archive (Rainbow Passage readings), a 2-minute formal speech recording (the Gettysburg Address), and a short segment of historical archival audio (Martin Luther King Jr.).
Overall results
# | Provider | WER | Median speed | Uptime |
|---|---|---|---|---|
1 | Cohere Transcribe | 3.2% | 1.42s | 99% |
2 | AssemblyAI | 3.3% | 3.94s | 100% |
3 | OpenAI Whisper | 3.6% | 2.41s | 100% |
4 | Deepgram Nova-2 | 4.6% | 1.34s | 100% |
Cohere Transcribe finished first on accuracy with a 3.2% duration-weighted WER, narrowly ahead of AssemblyAI (3.3%) and Whisper (3.6%). Deepgram Nova-2 trailed at 4.6%.
Speed: Deepgram leads, Cohere close behind
Provider | Median response time |
|---|---|
Deepgram Nova-2 | 1.34s |
Cohere Transcribe | 1.42s |
OpenAI Whisper | 2.41s |
AssemblyAI | 3.94s |
Deepgram and Cohere were effectively tied for speed, both returning results 2-3x faster than Whisper and roughly 3x faster than AssemblyAI. A caveat: AssemblyAI uses an asynchronous API (upload, then poll for results), which inflates its wall-clock time compared to the synchronous endpoints the other three offer. All timings include network latency from a single test location and are not a measure of pure model inference speed.
Cohere's blog post reports throughput using RTFx (real-time factor multiple) measured on local GPU inference, which is a more precise metric for model-level performance but not directly comparable to API response times.
Accented English: the hardest test
Indian-accented and French-accented English readings of the Rainbow Passage pushed all providers harder than any other test condition.
Deepgram struggled the most, recording 9.7% WER on Indian-accented speech and 11.2% on French-accented speech. On one sample, it transcribed phonetically plausible but semantically wrong phrases, substituting entire clauses rather than individual words.
Whisper and Cohere handled both accents well, staying in the 1-3% WER range. AssemblyAI landed in between.
This matters for any global deployment. ASR systems that perform well on standard American or British English can degrade sharply when confronted with the range of accents found in international business settings.
Long-form accuracy: a different picture
On the longest sample in our test set, a 125-second recording of the Gettysburg Address, the rankings shifted.
Provider | WER (Gettysburg Address) |
|---|---|
Deepgram Nova-2 | 0.4% |
AssemblyAI | 0.4% |
OpenAI Whisper | 1.1% |
Cohere Transcribe | 3.0% |
Deepgram and AssemblyAI were near-perfect on this long-form sample. Whisper was excellent. Cohere, despite winning the overall benchmark, had the highest error rate on the longest audio. This is an interesting tension: the model that performed best in aggregate was weakest on extended continuous speech.
For enterprise use cases involving meeting transcription or long call recordings, this is a gap worth watching. The model card notes that audio longer than 35 seconds is automatically split into overlapping chunks and reassembled, and chunking artifacts could account for some of the long-form degradation.
All in all, Cohere Transcribe enters the market as a genuine contender. A 3.2% WER, second-fastest response time, and best-in-class noise robustness is a strong debut for a company's first ASR model.
Editorial Transparency
This article was produced with the assistance of AI tools as part of our editorial workflow. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
Introducing Cohere Transcribe: a new state-of-the-art in open-source speech recognition — Cohere Team, Cohere, March 26, 2026
Primary - 2.
CohereLabs/cohere-transcribe-03-2026 - Model Card — Cohere Labs, Hugging Face, March 26, 2026
Open-weights model card with architecture details, usage instructions, and disclosed limitations.
Primary - 3.
Create a transcription - Cohere API Reference, Cohere
API documentation for the v2/audio/transcriptions endpoint.
Primary - 4.
Standardized benchmark evaluating ASR systems across curated datasets using word error rate.
Primary - 5.
speech-to-text-benchmark — bighippoman (Joseph Nordqvist), GitHub, March 27, 2026
Open-sourced benchmark code for the four-provider ASR comparison conducted for this article.
Primary
Was this useful?
More in Products
View all- Claude Code now remembers what it learns between sessionsFebruary 27, 2026
- Google launches Nano Banana 2, bringing pro-level image generation to its Flash modelFebruary 26, 2026
- Anthropic launches Remote Control for Claude Code, enabling mobile accessFebruary 25, 2026
- Claude Code Security, an AI-powered vulnerability scannerFebruary 20, 2026
Related stories
OpenClaw creator Peter Steinberger joins OpenAI as OpenClaw shifts to a foundation
February 15, 2026
ProductsManus adds Project Skills to its AI agent platform
Manus has introduced a feature called Project Skills that lets teams curate and lock sets of reusable AI workflows at the project level.
February 14, 2026
ProductsGoogle Docs adds Gemini-powered audio summaries
Google is rolling out a new Gemini feature in Google Docs that lets you listen to a short audio summary of a document.
February 14, 2026
IndustryAirbnb says AI now handles nearly 30% of English-language support tickets in North America
February 14, 2026