Gemma 4 on an iPhone: here's what a 2B model can actually do
Written by Joseph Nordqvist/April 8, 2026 at 4:21 AM UTC
4 min read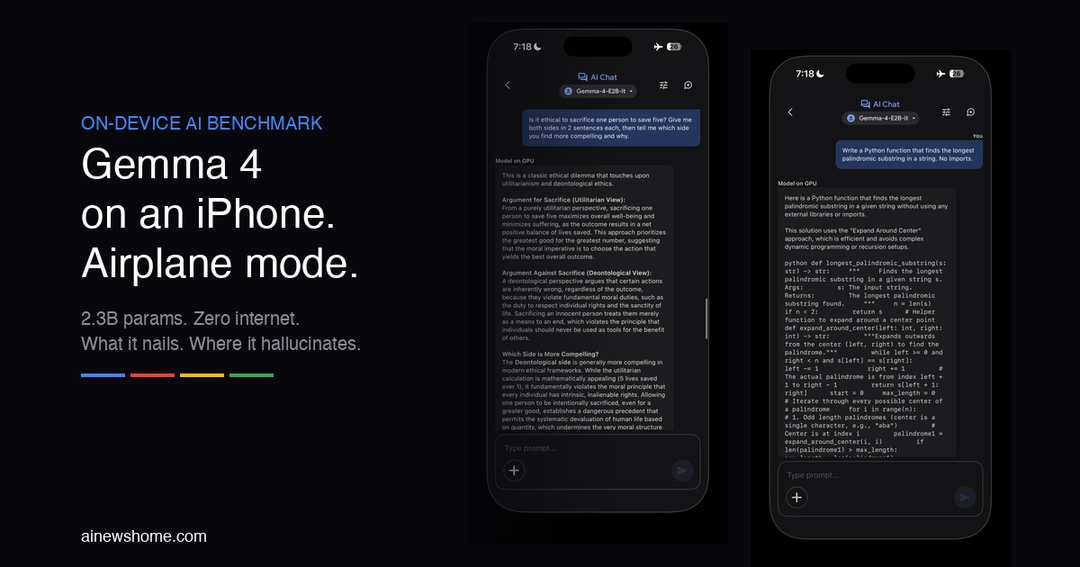
Google released Gemma 4 on April 2; four open models under Apache 2.0. The smallest, E2B, is 2.54 GB and it can run entirely on your phone. No internet, no API key, no account.
I downloaded it through the Google AI Edge Gallery app, turned on airplane mode, and started throwing prompts at it.
What it gets right
I ran seven tests in airplane mode. The reasoning tasks were surprisingly strong.
A Bayesian probability problem: three boxes, colored balls, what's the probability you picked Box A given you drew red? It produced a complete, correct proof. Prior probabilities, law of total probability, Bayes' theorem, right answer (2/3). With LaTeX rendering. On a phone. 18.9 seconds.
A coding prompt: write a longest palindromic substring function, no imports. Clean O(n²) expand-around-center algorithm, typed annotations, edge cases handled, test examples included. 30.1 seconds for the whole thing.
An ethics question: is it ethical to sacrifice one to save five, pick a side. It laid out utilitarian vs. deontological arguments, chose deontological, and defended the choice. No hedging, no "as an AI I can't." 8.9 seconds.
I also sent a photo of my cat through the vision feature. It nailed the description (pose, setting, lighting, mood) but called my Bengal cat a "tabby." 9.9 seconds.
What it gets wrong
I asked it to write about the fall of the Western Roman Empire with specific emperors, dates, and events.
The structure was great; four chronological phases, clear cause-and-effect, proper essay format. But it invented an emperor ("Marcus Didius Julius Caesar"), put Caracalla in the wrong century, reversed the direction of the Vandal migration, called Odoacer a "kingmaker" instead of King of Italy, and left out Theodosius I, Alaric's sack of Rome, and Attila the Hun entirely. Seven factual errors in one answer.
The pattern across all the tests is consistent: strong reasoning, weak recall. It can think through a Bayesian proof but can't remember which emperor ruled when. It can describe a cat in detail but can't identify the breed. The model learned how to reason, not what to know.
This tracks with Google's own numbers. E2B scores 60% on MMLU Pro (a knowledge benchmark) — a 25-point gap below the 31B model. Google's model card says directly: these models "are not knowledge bases."
It also explains why the app has an Agent Skills feature. When you're online, it can query Wikipedia and call external APIs to fill in the gaps. Offline, you get the reasoning engine without the encyclopedia.
The specs
Model | Active / Total Params | Context | MMLU Pro | Modalities |
|---|---|---|---|---|
E2B | 2.3B / 5.1B | 128K | 60.0% | Text, Image, Audio |
E4B | 4.5B / 8B | 128K | 69.4% | Text, Image, Audio |
26B A4B (MoE) | 3.8B / 25.2B | 256K | 82.6% | Text, Image |
31B (Dense) | 30.7B | 256K | 85.2% | Text, Image |
The "E" in E2B stands for "effective" — the active parameter count during inference. The total is higher (5.1B) because of Per-Layer Embeddings, which give each decoder layer its own small embedding lookup table. Combined with 2-bit and 4-bit quantization, this lets the model run in under 1.5 GB of memory on supported devices. The whole stack runs on LiteRT-LM, Google's open-source inference framework.
The bottom line
Gemma 4 E2B is not replacing cloud AI. It hallucinates facts, it can't access current information, and Google says as much in the model card.
But a 2.54 GB file on your phone just solved a Bayesian probability problem, wrote a correct algorithm, argued ethics, and described a photo.. all in airplane mode, all on-device, all with zero data leaving the device. For code help, drafting, math, and structured thinking, it works.
Transparency
All tests ran on an iPhone in airplane mode using Google AI Edge Gallery with Gemma-4-E2B-it (2.54 GB). Response times are as reported by the app. Screenshots are unmodified. The Roman Empire answer was fact-checked against primary historical sources. Claude Opus 4.6 assisted with interactive component development.
Written by
Joseph Nordqvist
Joseph founded AI News Home in 2026. He studied marketing and later completed a postgraduate program in AI and machine learning (business applications) at UT Austin’s McCombs School of Business. He is now pursuing an MSc in Computer Science at the University of York.
View all articles →This article was written by the AI News Home editorial team with the assistance of AI-powered research and drafting tools. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
- 2.
- 3.
Bring state-of-the-art agentic skills to the edge with Gemma 4, Google Developers Blog, April 2, 2026
Primary - 4.
- 5.
- 6.
- 7.
Was this useful?