Google's new voice model powers Search Live expansion
Written by Joseph Nordqvist/March 26, 2026 at 9:25 PM UTC
4 min read
Google released Gemini 3.1 Flash Live on March 26, positioning it as the company's most capable real-time audio model to date. The launch comes as competition in voice AI intensifies, with OpenAI, xAI, Alibaba, and others all racing to build models that can hold natural, real-time spoken conversations.
Google is also using 3.1 Flash Live to power the global expansion of Search Live, its real-time voice and video search feature, to more than 200 countries and territories.
That makes this as much a product story as a model story, with Google betting that better voice infrastructure can extend its search dominance into a new modality.
What the model does
Gemini 3.1 Flash Live is a specialized audio and voice model built on the Gemini 3 Pro architecture. It accepts audio, image, video, and text input with a 128K token context window, and outputs audio and text with up to 64K tokens.
The practical improvements center on three areas. First, lower latency: Google says the model delivers faster responses with fewer pauses than its predecessor, Gemini 2.5 Flash Native Audio. Second, better tonal understanding: it can detect acoustic cues like pitch, pace, and signs of frustration or confusion, and adjust its responses accordingly. Third, improved noise filtering: the model is better at separating speech from environmental sounds like traffic or television.
Google also reports that Gemini Live can now follow a conversation thread for twice as long as with the previous model [1], a meaningful improvement for extended brainstorming or complex troubleshooting sessions.
The competitive picture
The voice AI space has grown crowded fast. Google's launch puts 3.1 Flash Live up against OpenAI's GPT-Realtime models, xAI's Grok Voice Agent, Alibaba's Qwen 3 Omni, Amazon's Nova 2.0 Sonic, and StepFun's Step-Audio R1.1, among others.
On benchmarks, the results are generally favorable for Google.
The model leads on Scale AI's Audio MultiChallenge, a test of multi-turn conversational reasoning under real-world audio conditions, scoring 36.1% with thinking enabled versus 34.7% for OpenAI's GPT-Realtime 1.5.
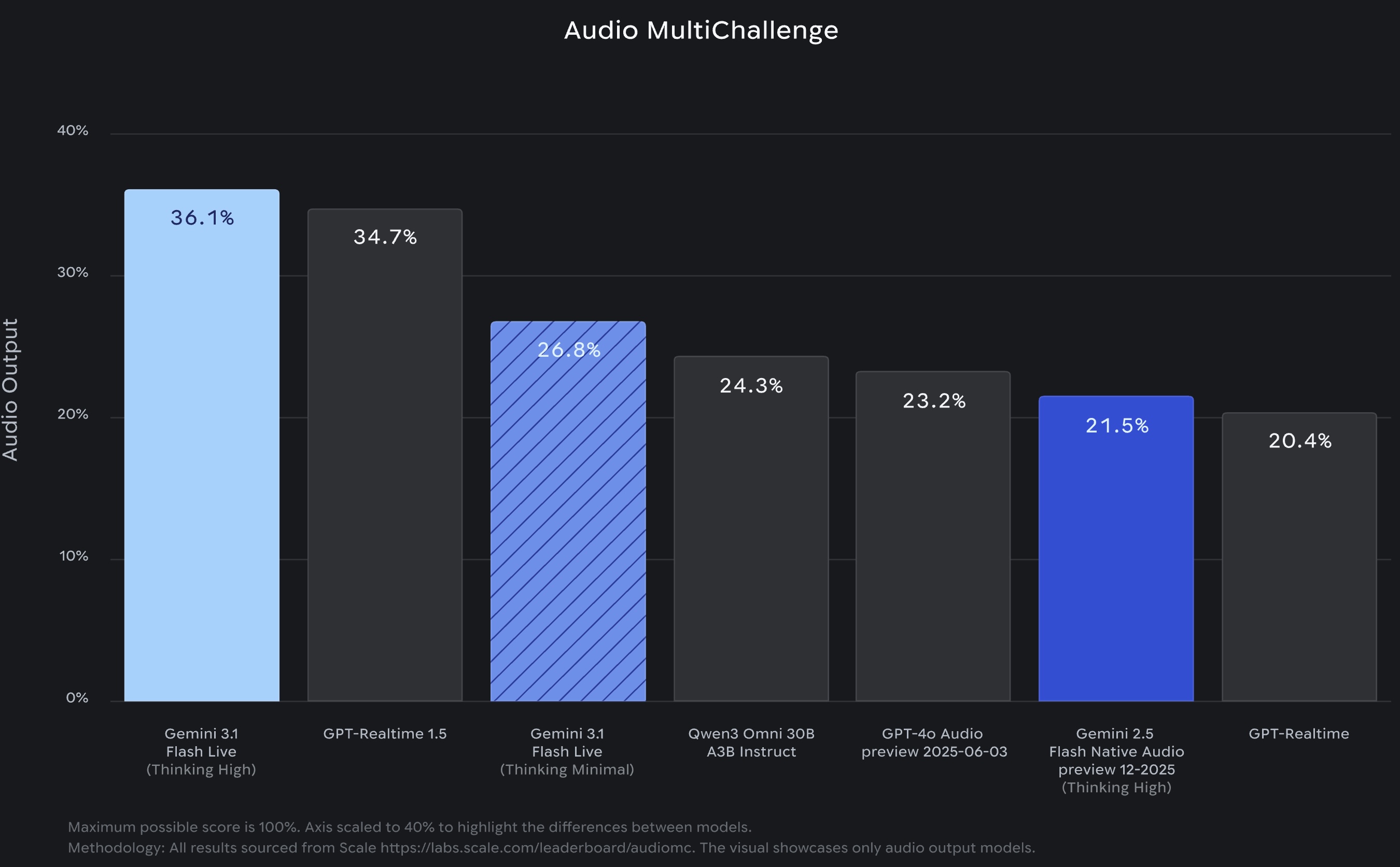
It also tops ComplexFuncBench Audio, which measures multi-step function calling, at 90.8%. On Big Bench Audio, which tests speech reasoning, it places second at 95.9% behind StepFun's Step-Audio R1.1 at 97.0%.
Search Live goes global
The most immediate consumer impact is the expansion of Search Live. The feature, which allows users to have real-time voice and video conversations with Google Search, is now available in every country and territory where AI Mode is active. Google says the model supports more than 90 languages, making it one of the broadest multilingual voice AI deployments to date.
The expansion turns Search Live from a limited preview into a global product. Users can point their camera at something, ask a question by voice, and have a back-and-forth conversation with Search about what they are seeing (video from Google’s blog showcasing this feature below).
It is essentially a multimodal search interface powered by the new audio model.
Enterprise and developer access
On the enterprise side, 3.1 Flash Live is available through Gemini Enterprise for Customer Experience, Google's contact center product. Verizon, LiveKit, and The Home Depot are among the companies Google cites as early adopters.
For developers, the model is available in preview through the Gemini Live API in Google AI Studio. A separate developer-focused blog post highlights improvements to tool calling and instruction following during live conversations, capabilities that matter for building voice agents that need to take actions, not just talk.
Safety measures
All audio generated by 3.1 Flash Live is watermarked with SynthID, Google's AI content identification system. The watermark is embedded directly in the audio output and is designed to be imperceptible to listeners while remaining detectable by automated systems. As AI-generated voice content becomes more common, watermarking is increasingly seen as a baseline expectation rather than a differentiator.
Why it matters
The voice AI race is becoming more about whether they can listen well enough, reason fast enough, and act reliably enough to replace workflows that currently require screens and keyboards.
The question now is whether users and developers adopt it at scale, or whether voice remains a secondary input for most people. The global Search Live expansion is Google's bet that the infrastructure is finally good enough to find out.
Editorial Transparency
This article was produced with the assistance of AI tools as part of our editorial workflow. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
Gemini 3.1 Flash Live: Making audio AI more natural and reliable — Valeria Wu,Yifan Ding, Google, March 26, 2026
Primary - 2.
- 3.Primary
- 4.
Was this useful?
More in Products
View all- Claude Code now remembers what it learns between sessionsFebruary 27, 2026
- Google launches Nano Banana 2, bringing pro-level image generation to its Flash modelFebruary 26, 2026
- Anthropic launches Remote Control for Claude Code, enabling mobile accessFebruary 25, 2026
- Claude Code Security, an AI-powered vulnerability scannerFebruary 20, 2026
Related stories
OpenClaw creator Peter Steinberger joins OpenAI as OpenClaw shifts to a foundation
February 15, 2026
ProductsManus adds Project Skills to its AI agent platform
Manus has introduced a feature called Project Skills that lets teams curate and lock sets of reusable AI workflows at the project level.
February 14, 2026
ProductsGoogle Docs adds Gemini-powered audio summaries
Google is rolling out a new Gemini feature in Google Docs that lets you listen to a short audio summary of a document.
February 14, 2026
IndustryAirbnb says AI now handles nearly 30% of English-language support tickets in North America
February 14, 2026