Google releases Gemini 3.1 Flash-Lite
Written by Joseph Nordqvist/March 3, 2026 at 9:06 PM UTC
2 min readGoogle has released a preview of Gemini 3.1 Flash-Lite, positioning it as the fastest and most cost-efficient model in the Gemini 3 series. The model is available now via Google AI Studio and Vertex AI.
Google chief scientist Jeff Dean described it on X as setting "a new standard for efficiency and capability.” He also shared a side-by-side speed comparison comparing Gemini 3.1 Flash-Lite against the 2.5 Flash Model.
Pricing and benchmarks
Where Gemini 2.5 Flash-Lite ran at $0.10/$0.40 per million tokens, 3.1 Flash-Lite is priced at $0.25/$1.50. This represents a 150% increase on input and 275% on output.
Google's official benchmarks show 3.1 Flash-Lite leading its tier across most reasoning and multimodal tasks.
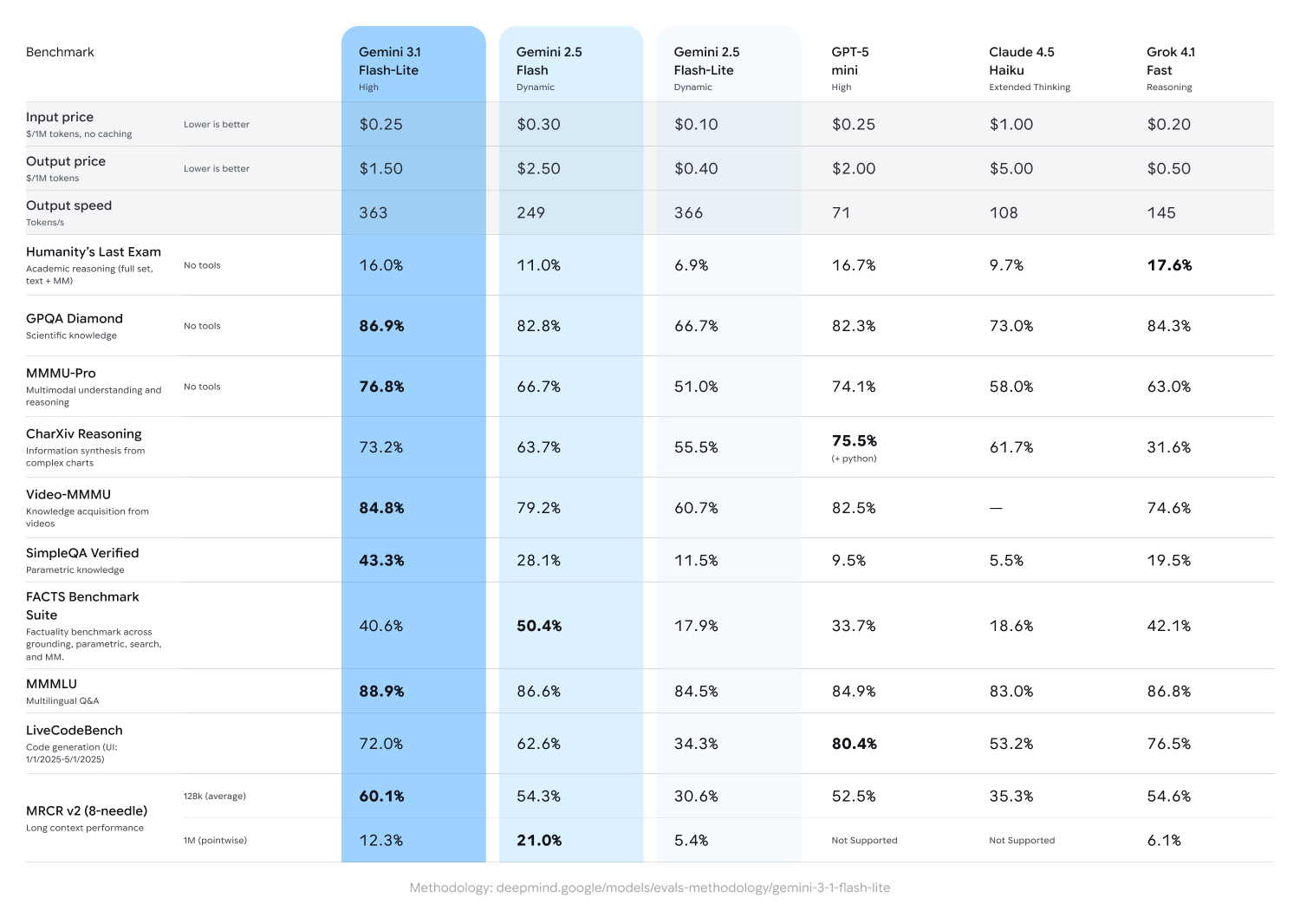
It should be noted that its comparison table notably omits Gemini 3 Flash in favor of 2.5 Flash, which makes the performance gains look larger than a same-generation comparison might show. Also, Google's table benchmarks 3.1 Flash-Lite at 'High' thinking while testing both 2.5 Flash models at 'Dynamic'.
The results
Gemini 3.1 Flash-Lite scored 86.9% on GPQA Diamond, above both Gemini 2.5 Flash (82.8%) and Claude 4.5 Haiku (73.0%).
On MMMU-Pro, a multimodal reasoning benchmark, it reached 76.8%, outpacing GPT-5 mini (74.1%) and Grok 4.1 Fast (63.0%).
The model also posted 84.8% on Video-MMMU and 88.9% on MMMLU, leading its comparison set on both.
Not every result favors the new model though.
On the FACTS Benchmark Suite, which tests factuality across grounding, parametric, and search tasks, 3.1 Flash-Lite scored 40.6% against Gemini 2.5 Flash's 50.4%.
GPT-5 mini led on LiveCodeBench at 80.4%, compared to 3.1 Flash-Lite's 72.0%.
While on Humanity's Last Exam, Grok 4.1 Fast edged ahead at 17.6% versus 16.0%.
Thinking levels
Google engineered the model with what it calls "thinking levels," allowing it to respond instantly to high-volume queries while scaling up reasoning for more complex inputs. The feature ships as standard in both AI Studio and Vertex AI, giving developers direct control over how much the model reasons per request.
Written by
Joseph Nordqvist
Joseph founded AI News Home in 2026. He studied marketing and later completed a postgraduate program in AI and machine learning (business applications) at UT Austin’s McCombs School of Business. He is now pursuing an MSc in Computer Science at the University of York.
View all articles →This article was written by the AI News Home editorial team with the assistance of AI-powered research and drafting tools. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
Gemini 3.1 Flash-Lite: Built for intelligence at scale — The Gemini Team, Google, March 3, 2026
Primary
Was this useful?