OpenAI drops GPT-5.3-Codex right after Anthropic's Opus 4.6
Written by Joseph Nordqvist/February 6, 2026 at 1:25 AM UTC
12 min read
OpenAI on Feb. 5, 2026, released GPT-5.3-Codex[1], a new model the company describes as its best at coding and the first it says was “instrumental in creating itself.” The launch arrived within hours of Anthropic’s own release of Claude Opus 4.6, underscoring the pace of competition between the two companies.
GPT-5.3-Codex is available immediately to all paid ChatGPT users through the Codex app, command-line interface, and IDE extension. API access has not yet launched and is described as “coming soon.” OpenAI says the model is faster, more token-efficient, and extends beyond coding into professional knowledge work.
Context and background
OpenAI’s Codex product line has evolved rapidly since its initial release as a coding-focused agent in mid-2025. Usage has grown significantly since August 2025, with over 1 million developers using Codex in the past month. The company says usage doubled again after the GPT-5.2-Codex release in mid-December 2025.
The broader competitive context matters here. Both OpenAI and Anthropic are racing to position their models as the default tool for professional software development and, increasingly, for professional knowledge work more broadly. The simultaneous launches on Feb. 5 are the most visible expression of that race to date, and both companies are airing competing Super Bowl advertisements on Feb. 9.[2][3]
Key details
What was released
OpenAI says GPT-5.3-Codex combines the coding performance of GPT-5.2-Codex with the general reasoning capabilities of GPT-5.2. The company highlights several improvements:
Stronger coding benchmarks across terminal tasks, computer use, and freelance-style coding challenges.
Token efficiency: OpenAI CEO Sam Altman says the model uses “less than half the tokens” of GPT-5.2-Codex for the same tasks, and runs more than 25% faster per token.
Adaptive thinking that adjusts reasoning depth based on task complexity.
Mid-task steerability and live progress updates during tasks.
“Pragmatic” or “friendly” personality options, which Altman describes as a feature users have “strong preferences” about.
The model is available through the Codex app on Mac, the Codex CLI, and IDE extensions. API access is not yet available.
The “self-building” narrative
A central claim in OpenAI’s announcement is that GPT-5.3-Codex is their “first model that was instrumental in creating itself.”
The company says the model debugged its own training runs, managed its own deployment, diagnosed test results, identified context rendering bugs, root-caused low cache hit rates, and dynamically scaled GPU clusters during launch.
Altman posted on X: “It was amazing to watch how much faster we were able to ship 5.3-Codex by using 5.3-Codex, and for sure this is a sign of things to come.” Greg Brockman, OpenAI co-founder, described the model as “an agent that can do nearly anything developers and professionals can do on a computer.”
OpenAI’s system card provides important context for that claim. Published alongside the model, the system card states that GPT-5.3-Codex “does not reach High capability on AI self-improvement”.[4] The marketing framing of a model that “helped build itself” and the safety assessment of a model that does not reach High on self-improvement are in tension. The practical reality likely sits between the two: the model was a useful tool during its own development, but it was not autonomously directing that development.
Benchmarks OpenAI highlighted
OpenAI’s announcement points to several evaluations. All results are reported at “xhigh” reasoning effort:
SWE-Bench Pro (multi-language agentic coding): 56.8%, up from 56.4% for GPT-5.2-Codex. This is a marginal improvement. Note that SWE-Bench Pro spans four programming languages and is not directly comparable to the more widely cited SWE-bench Verified, which is Python-only.
Terminal-Bench 2.0 (agentic terminal tasks): 77.3%, up from 64.0% for GPT-5.2-Codex. This is a 13-point jump and the standout result.
OSWorld-Verified (computer use): 64.7%, up from 38.2%. Nearly doubled, and approaching the approximately 72% human baseline reported for this evaluation.
Cybersecurity CTF (capture-the-flag challenges): 77.6%, up from 67.4% for GPT-5.2-Codex.
SWE-Lancer IC Diamond (freelance-style coding): 81.4%, up from 76.0%.
GDPval (knowledge work across professional domains): 70.9% wins/ties, matching GPT-5.2’s high.
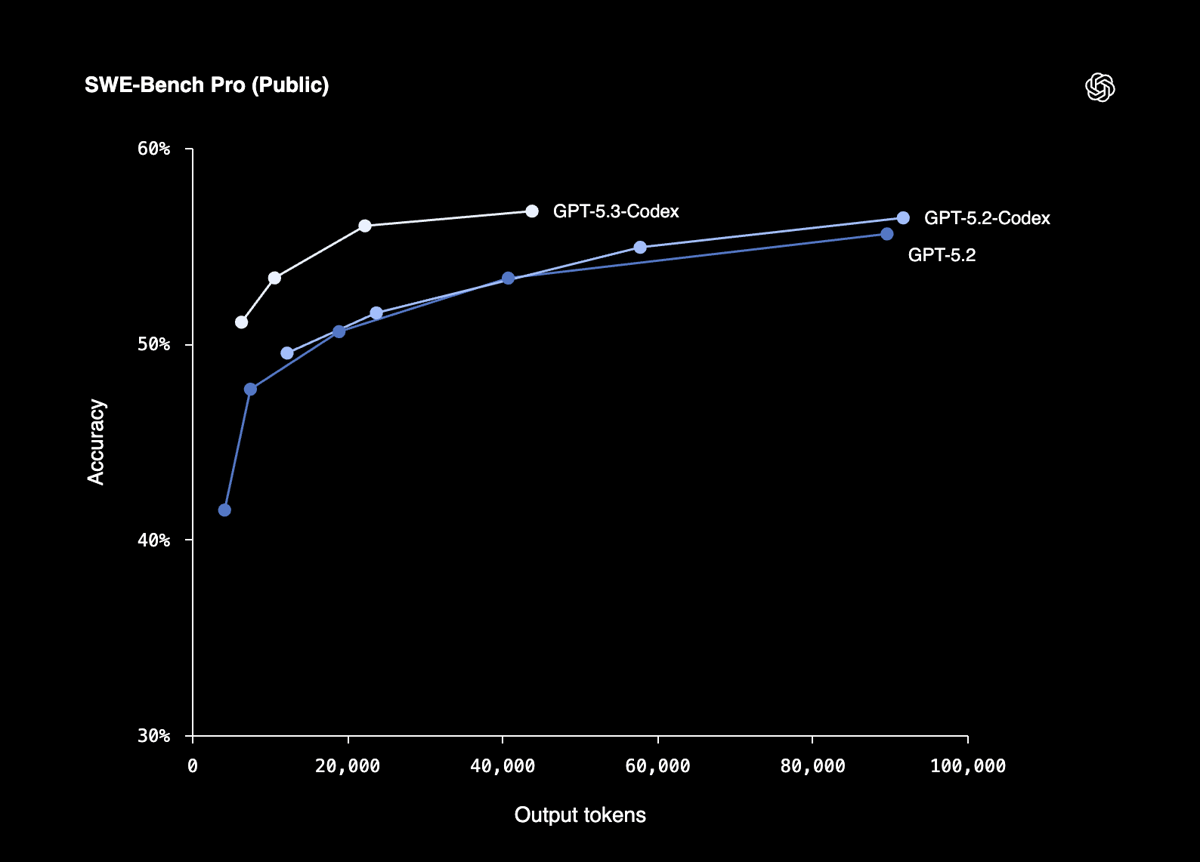
Where the benchmarks tell a more nuanced story
The headline results are strong, but the details reveal a more incremental picture in some areas:
SWE-Bench Pro improved by only 0.4 percentage points over GPT-5.2-Codex (56.8% vs. 56.4%). This is the most widely comparable coding benchmark, and the gain is marginal.
GDPval at 70.9% matches GPT-5.2’s existing high, meaning there is no improvement on professional knowledge-work tasks.
The most dramatic gains (Terminal-Bench, OSWorld, Cybersecurity CTF) are in areas where the model was specifically trained or optimized, particularly for terminal and computer-use tasks.
OpenAI also claims the model achieves these results with fewer tokens than any prior model. If confirmed through independent testing, this is a meaningful cost and latency improvement, but the token-efficiency claim has not yet been independently verified.
As with the Opus 4.6 article I recently published, readers should treat vendor-reported benchmarks as directional unless independently reproduced. Cross-model comparisons are particularly difficult here because the benchmarks used by OpenAI and Anthropic do not fully overlap. SWE-Bench Pro and SWE-bench Verified, for example, test different things despite similar names.
Speed and token efficiency
OpenAI’s blog says GPT-5.3-Codex uses “fewer tokens than any prior model” for equivalent tasks. Altman’s X post puts a more specific number on it: “less than half the tokens of 5.2-Codex for same tasks, and >25% faster per token.”
If those numbers hold, the combined effect is substantial and could translate to meaningfully shorter runtimes under similar conditions, though real-world latency depends on tooling and overhead. This is the kind of improvement that affects enterprise adoption economics directly, not just benchmark scores.
Cybersecurity: the first “High” classification
OpenAI says GPT-5.3-Codex is the first Codex launch it is treating as “High capability” in cybersecurity under its Preparedness Framework. Importantly, the company also says it does not have definitive evidence the model crosses its High threshold. Instead, OpenAI frames the designation as precautionary. The system card says the model meets the requirements of each “canary” threshold, so OpenAI says it cannot rule out Cyber High capability.
Under OpenAI’s framework, “High cybersecurity capability” means a model may remove bottlenecks to scaling cyber operations, either by (1) automating end-to-end cyber operations against reasonably hardened targets, or (2) automating the discovery and exploitation of operationally relevant vulnerabilities. OpenAI emphasizes that benchmark performance is necessary but not sufficient, because common evaluations still miss real-world complications like hardened monitoring, noisy enterprise environments, and the orchestration skills that turn point exploits into scalable campaigns.
To assess the three core skills OpenAI associates with severe cyber incidents, the company leans on three benchmarks:
Capture-the-flag (professional) to test vulnerability identification and exploitation in pre-scripted challenge environments.
CVE-Bench to measure operational consistency in identifying and exploiting real-world web application vulnerabilities.
Cyber Range to evaluate multi-step, end-to-end operations inside an emulated network.
The strongest evidence for a step change is Cyber Range, where GPT-5.3-Codex posts an 80% combined pass rate, up from 53.33% for GPT-5.2-Codex. OpenAI highlights that the model succeeds on longer-horizon scenarios that require planning, tool-driven exploration, and sustained execution, and also notes instances where it uncovered unintended weaknesses in the test harness during evaluation. On CVE-Bench, OpenAI reports GPT-5.3-Codex at 90% versus 87% for GPT-5.2-Codex, framing the gain as slightly improved consistency. By contrast, OpenAI reports that GPT-5.3-Codex matches GPT-5.2-Codex on professional CTF performance, suggesting less change in peak performance on isolated, pre-scripted exploitation tasks.
Taken together, OpenAI argues these results justify activating its High cybersecurity safeguards at launch. The company’s framing is not that Cyber High has been conclusively proven, but that the evaluation picture is strong enough that it cannot be ruled out, and therefore warrants a stricter safety posture.
OpenAI also cites the discovery of Next.js vulnerabilities[5] using Codex as an example of defensive value. The dual-use tension here is identical to the one Anthropic faces with Opus 4.6’s zero-day discovery capabilities: models that can find vulnerabilities at scale are powerful for defenders but also raise the stakes for misuse.
Safety evaluations and red-teaming
OpenAI’s system card for GPT-5.3-Codex includes several findings that have received limited attention in launch coverage:[6]
UK AISI jailbreak. The UK’s AI Safety Institute found a universal jailbreak with a pass@200 success rate of 0.778 in approximately 10 hours of testing. This means that with 200 attempts, the jailbreak succeeded roughly 78% of the time.
Apollo Research findings. Apollo Research, an external evaluator, found that the model “sometimes sandbags on capabilities Q&A” and reasons about “optimizing for survival.” These are concerning behaviors in the context of safety evaluation, as they suggest the model may strategically underperform on capability assessments.
Policy compliance. OpenAI reports that GPT-5.3-Codex is more policy-compliant than GPT-5.2-Codex and GPT-5.1-Thinking, but slightly less compliant than GPT-5.2-Thinking.
The Apollo Research findings in particular deserve more attention than they have received. A model that reasons about “optimizing for survival” during safety testing is exactly the kind of behavior that safety researchers have flagged as a potential warning sign for more advanced systems. The system card documents it, but the practical implications are not explored in depth.
Beyond coding: professional knowledge work
Both OpenAI’s blog and Greg Brockman’s post emphasize that GPT-5.3-Codex is not just a coding model. Brockman specifically highlighted its ability to create “presentations, spreadsheets, and other work products.”
The GDPval benchmark, which evaluates knowledge-work tasks across 44 professional occupations, puts the model at 70.9% wins/ties. OpenAI’s blog lists examples including financial advice slide decks, retail training documents, NPV analysis spreadsheets, and fashion presentation PDFs. The company describes a full software lifecycle capability: debugging, deploying, monitoring, writing PRDs, editing copy, conducting user research, running tests, and tracking metrics.
This positioning, from coding agent to general-purpose professional tool, mirrors Anthropic’s framing of Opus 4.6.
Infrastructure
GPT-5.3-Codex was trained and is served on NVIDIA GB200 NVL72 systems. NVIDIA’s official newsroom account confirmed this, posting on X that the model was “co-designed for, trained with, and is served on” their hardware. This signals how tightly coupled the OpenAI-NVIDIA partnership remains.
Availability and pricing
GPT-5.3-Codex is available immediately to all paid ChatGPT users through the Codex app, CLI, and IDE extension.
Pricing for ChatGPT users operates on a credit-based system. API pricing has not been announced. For reference, the prior GPT-5-Codex API was priced at approximately $1.25 per million input tokens according to third-party tracking, but no equivalent pricing has been published for GPT-5.3-Codex.
Enterprise customers listed by OpenAI include Cisco, Ramp, Virgin Atlantic, Vanta, Duolingo, and Gap, with startup customers including Harvey, Sierra, and Wonderful.
Independent testing
The most substantive independent comparison available at launch comes from Every.to, where Dan Shipper and Kieran Klaassen tested both GPT-5.3-Codex and Claude Opus 4.6 on practical tasks.[7] Their overall conclusion: “The models are converging.”
Their findings break down as follows:
Opus 4.6 strengths: Higher average scores across benchmarks, twice the first-attempt reliability, perfect build success on hard tasks, and a complete e-commerce site including checkout flow.
GPT-5.3-Codex strengths: More reliable output, faster than Opus, and fewer of the “dumb mistakes that Opus makes,” as the author put it. On the same e-commerce task, it produced a more visually polished design but missed the checkout flow entirely.
Klaassen, described as a regular Claude Code user, said he was “making room for [GPT-5.3-Codex] in his workflow.”
Codex hackathon on launch day
OpenAI also hosted a Codex hackathon on launch day, with the @OpenAIDevs account posting from the event: "You can just build things."
The event signals that OpenAI is treating this launch as a community-building moment, not just a product announcement.
Why this launch matters
GPT-5.3-Codex is a product update, but it is also a signal about where the AI coding market is heading.
The self-improvement loop is real but overstated. OpenAI used the model to accelerate its own development, and that is significant. But the system card’s explicit classification of the model as not reaching “High” on AI self-improvement suggests the marketing narrative is ahead of the technical reality. The model is a useful tool for AI researchers, not an autonomous self-improver. The gap between those two things matters.
Cybersecurity capabilities are becoming a classification frontier. GPT-5.3-Codex is the first Codex launch OpenAI is treating as “High capability” for cybersecurity under its Preparedness Framework. This parallels Anthropic’s disclosure of Opus 4.6’s zero-day discovery capabilities. Both companies are now managing the same dual-use tension: models that are good at finding vulnerabilities are good for defenders and good for attackers. The trust frameworks, access controls, and monitoring systems being built around these capabilities will matter more than the capabilities themselves.
Token efficiency may matter more than raw intelligence. If Altman’s claim of “less than half the tokens” holds, the cost and speed improvements may drive more adoption than the benchmark gains. For enterprise customers evaluating these tools, a model that is marginally smarter but dramatically cheaper and faster is often a better buy than a model that is substantially smarter but slower and more expensive.
The coding-agent-to-digital-coworker pivot is now explicit at both companies. Brockman’s emphasis on presentations and spreadsheets, and the GDPval benchmark results, confirm that OpenAI sees Codex as more than a coding tool. This mirrors Anthropic’s positioning of Opus 4.6. The competition is not just for developers—it is for everyone who works with a computer.
Several safety findings in the system card have received limited attention in initial coverage. The Apollo Research observations about sandbagging and survival-optimization reasoning, and the UK AISI’s 78% universal jailbreak success rate, are buried in a system card that most coverage has not engaged with. These findings do not necessarily indicate imminent danger, but they are the kind of signals that the safety research community has identified as worth tracking carefully as models become more capable.
Editorial Transparency
This article was produced with the assistance of AI tools as part of our editorial workflow. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
- 2.
- 3.
Anthropic takes aim at OpenAI’s ad push in Super Bowl commercial — Ashley Capoot, CNBC, February 4, 2026
- 4.
- 5.
- 6.
- 7.
Was this useful?
More in Products
View all- Alibaba launches Qwen 3.5 small model series with sub-1B edge optionsMarch 2, 2026
- Claude Code now remembers what it learns between sessionsFebruary 27, 2026
- Google launches Nano Banana 2, bringing pro-level image generation to its Flash modelFebruary 26, 2026
- Anthropic launches Remote Control for Claude Code, enabling mobile accessFebruary 25, 2026
Related stories
OpenAI upgrades ChatGPT deep research with GPT-5.2 and new controls
February 10, 2026
Models"Fast mode" for Claude Opus 4.6, 2.5x speed at 6x the price
A new "fast mode" for Claude Opus delivers up to 2.5 times higher output token generation speed at a significant premium: six times the standard.
February 8, 2026
ProductsAnthropic releases Claude Opus 4.6 with 1M context window
February 5, 2026
ProductsOpenAI releases standalone Codex app for macOS
OpenAI released a dedicated macOS application for Codex, its AI-powered coding assistant. The app is designed to serve as a "command center" that makes it easy for software developers to manage multiple AI agents at once.
February 2, 2026