DeepSeek V4 ships with open weights and Huawei Ascend support, narrowing the gap with closed AI models
Written by Veronica Salvador/April 26, 2026 at 6:44 PM UTC
10 min read- 1.DeepSeek released V4 on April 24, 2026: V4-Pro (1.6T total / 49B active) and V4-Flash (284B / 13B active), both MIT-licensed, both with 1M-token context, both live on Hugging Face.
- 2.V4-Pro tops LiveCodeBench (93.5) and Codeforces (3,206 — rank 23 among human competitors), is within 0.2 points of Claude Opus 4.6 on SWE-Verified, and trails GPT-5.4 and Gemini-3.1-Pro on knowledge benchmarks by ~3–6 months — DeepSeek's own framing.
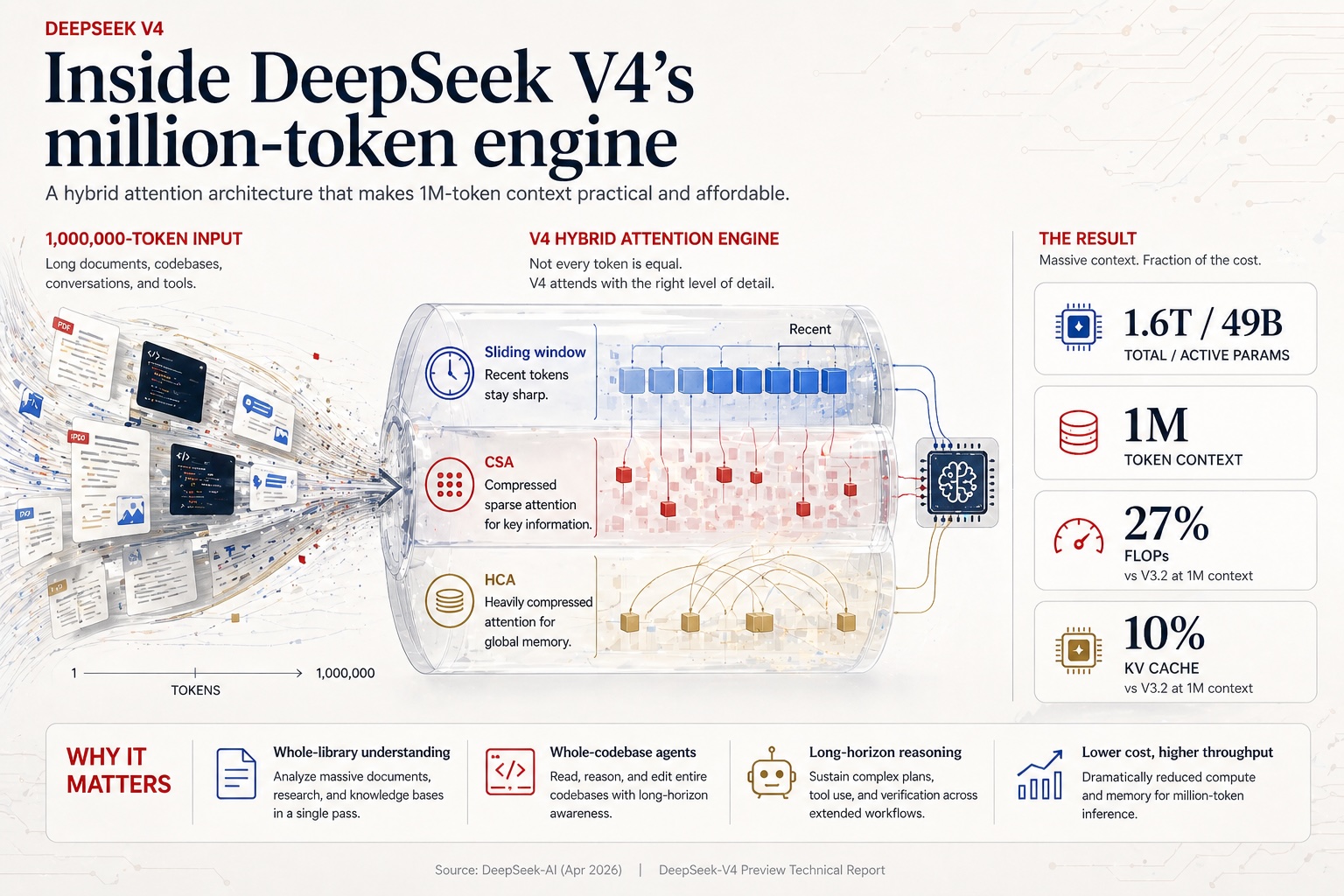
- 3.A new hybrid attention stack (Compressed Sparse Attention + Heavily Compressed Attention) with FP4 quantization-aware training cuts single-token inference FLOPs to 27% of DeepSeek V3.2 and KV cache size to 10% at the 1M context length.
- 4.The 13-word line buried on page 16 — "validated…on both NVIDIA GPUs and HUAWEI Ascend NPUs" — combined with Huawei's "full support" announcement on launch day, is the actual news for Western readers.
- 5.Alongside the launch, DeepSeek permanently cut cached-input prices by 10× across the entire API. With the active V4-Pro promo, cache-hit pricing runs roughly 139× cheaper than GPT-5.5 and 83× cheaper than Claude Sonnet 4.6 on the same workload.

DeepSeek released the preview version of its V4 model series on April 24, 2026 — the same Friday that Google disclosed it would invest up to $40 billion in Anthropic. The two stories are a pair. One is the largest single check ever written into a frontier AI lab. The other is a 58-page paper, posted to Hugging Face under the MIT license, describing how a Chinese research group has compressed the cost of running a million-token context model to roughly a quarter of what it was eight months ago — and quietly validated the whole thing on Huawei silicon.
The V4 series ships in two preview models. DeepSeek-V4-Pro is a 1.6-trillion-parameter Mixture-of-Experts model with 49 billion parameters activated per token. DeepSeek-V4-Flash is a 284-billion-parameter sibling with 13 billion activated. Both support a one-million-token context window. Both are released under the MIT license, with weights live on Hugging Face. Both are available immediately through DeepSeek's API at prices that undercut every comparable Western model by roughly an order of magnitude.
The headline benchmark numbers, as reported by DeepSeek, place V4-Pro ahead of Claude Opus 4.6, GPT-5.4, and Gemini-3.1-Pro on coding contests, within 0.2 points on SWE-Verified, and 3 to 6 months behind on knowledge and pure reasoning. The headline efficiency numbers are sharper still: at one million tokens, V4-Pro consumes 27% of the inference FLOPs and 10% of the KV cache that DeepSeek V3.2 needed for the same workload eight months ago.
What the paper is actually about
For all the geopolitical commentary the V4 release will attract, the paper itself is overwhelmingly an engineering document. Its title — Towards Highly Efficient Million-Token Context Intelligence — is descriptive. The 58 pages of LaTeX behind it lay out the four innovations DeepSeek claims as new contributions:
- Hybrid Attention with CSA and HCA. Two complementary attention variants are interleaved across layers. Compressed Sparse Attention (CSA) compresses every four-token block into a single KV entry, then runs DeepSeek Sparse Attention against the compressed cache via a "Lightning Indexer." Heavily Compressed Attention (HCA) consolidates 128 tokens into one entry and runs dense attention against the much smaller cache. The combination is the engine of the efficiency claim.
- Manifold-Constrained Hyper-Connections (mHC). A constraint on the residual mapping matrices — projected onto the manifold of doubly stochastic matrices via Sinkhorn-Knopp iterations — that DeepSeek says solves the numerical instability that has historically plagued naive hyper-connections.
- Muon optimizer with hybrid Newton-Schulz iterations. Replaces AdamW for most weights, paired with a custom 10-iteration Newton-Schulz orthogonalization scheme. AdamW is retained for embeddings, the prediction head, biases, and RMSNorm modules.
- FP4 Quantization-Aware Training. Applied to MoE expert weights — by far the largest GPU memory cost of an MoE model — and to the indexer's Query-Key path. The paper reports a 99.7% recall rate for KV-entry top-k selection at FP4 precision, with a 2× speedup on the selector.
None of these innovations are unprecedented in isolation. Muon, FP4 QAT, sparse attention, and hyper-connections each have prior art in 2024–2025 papers. What is novel is the assembly: a coherent stack that stays stable through 33 trillion training tokens at 1.6T-parameter scale and trains end-to-end on a domestic Chinese hardware target. The stability part is non-trivial — the paper devotes a full subsection to "mitigating training instability," disclosing two new techniques (Anticipatory Routing and SwiGLU clamping) that the authors flag as empirically effective but theoretically unexplained.
Where V4-Pro sits on the leaderboards
DeepSeek's own benchmark table — the closest thing the paper has to a marketing chart — is unusually honest about the gaps. Reading down the column for V4-Pro-Max, the maximum reasoning effort mode of V4-Pro, three patterns emerge.
On coding, V4-Pro tops the table. LiveCodeBench: 93.5% vs Claude Opus 4.6 at 88.8% and Gemini-3.1-Pro at 91.7%. Codeforces rating: 3,206 vs GPT-5.4 at 3,168 and Gemini at 3,052 — a rank of 23rd among human competitive programmers. SWE-Verified: 80.6%, within 0.2 points of Opus 4.6's 80.8%. The paper notes this is "the first time an open model has matched a closed model" on coding.
On knowledge and pure reasoning, V4-Pro trails the frontier. Humanity's Last Exam: 37.7% vs Gemini-3.1-Pro at 44.4%. MMLU-Pro: 87.5% vs Gemini at 91.0%. Apex: 38.3% vs Gemini at 60.9% and GPT-5.4 at 54.1%. The paper attributes the gap to a "developmental trajectory that trails state-of-the-art frontier models by approximately 3 to 6 months."
On long context, the picture is mixed. V4-Pro beats Gemini-3.1-Pro on the 1M-token MRCR benchmark (83.5% vs 76.3%) but trails Claude Opus 4.6 (92.9%). Retrieval performance is "highly stable within a 128K context window," with degradation visible only beyond 128K — a useful nuance for anyone planning to drop it into production at full 1M length.
On agentic tasks, V4-Pro is competitive but not dominant. Terminal Bench 2.0: 67.9% (vs GPT-5.4's 75.1%). HLE w/ tools: 48.2% (vs Opus 4.6's 53.1%). On an internal R&D coding benchmark DeepSeek built around 200 of its own engineering tasks, V4-Pro hits a 67% pass rate — roughly between Claude Sonnet 4.5 (47%) and Claude Opus 4.5 (70%), with Opus 4.6 Thinking at 80%. A separate internal survey of 85 DeepSeek developers found 91% rated V4-Pro as ready or close-to-ready to be their primary daily coding model.
The line on page 16
The line is in section 3.1, in a paragraph titled Performance and Open-Sourced Mega-Kernel: "We validated the fine-grained EP scheme on both NVIDIA GPUs and HUAWEI Ascend NPUs platforms." Thirteen words. No further elaboration. The CUDA-based mega-kernel implementation is open-sourced as MegaMoE, a component of DeepSeek's DeepGEMM library.
Outside the paper, the framing is louder. Huawei announced on April 24 that its Ascend supernodes would offer "full support" for V4 from launch day. Third-party reporting indicates that DeepSeek granted Huawei exclusive early-access to optimize for the new architecture, while withholding the same access from NVIDIA and AMD. The Ascend 950 — Huawei's current flagship — is positioned by analysts between NVIDIA's H100 and H200 in capability. Further generations (960, 970) are reportedly in pipeline.
The strategic implication is the cleanest in the AI stack to date. A frontier-adjacent open-source model, an open-source training and inference framework, and a domestic chip platform that the model has been pre-validated against. Whether or not the U.S. export-control regime intended to accelerate this outcome, V4 is what it accelerated.
Pricing as policy
Alongside the V4 launch, DeepSeek made one further pricing change that has been quieter in the press cycle but is structurally larger: a permanent 10× cut to cached-input prices across the entire API. Cache hits on V4-Pro now bill at $0.0145 per million tokens at list, dropping to $0.003625 with the 75% V4-Pro promotional discount applied through May 5, 2026. V4-Flash cache hits are $0.0028 per million tokens.
The reference points are not subtle. OpenAI prices cached input on GPT-5.5 at $0.50 per million tokens. Anthropic prices cached input on Claude Sonnet 4.6 at $0.30. With the V4-Pro promo applied, that is roughly 139× cheaper than GPT-5.5 and 83× cheaper than Sonnet 4.6 on the same workload type — the kind of multiple that flips build-vs-buy decisions across an entire customer base.
Uncached prices follow the same pattern at lower multiples. V4-Flash uncached input is $0.14 per million tokens, output $0.28. V4-Pro uncached lists at $1.74 input and $3.48 output, with the promo bringing those to roughly $0.435 and $0.87. GPT-5.5 lists at $5 input / $30 output; GPT-5.5 Pro at $30 / $180. At list, V4-Pro undercuts GPT-5.5 by about 9× on output cost. With the May-5 promo applied, the multiple is roughly 35×.
This is what pricing-as-policy looks like. The model is open-source, so anyone with sufficient inference hardware can run it locally. The hosted API prices — and especially the cache-hit prices, where most production agentic and chat workloads now spend the bulk of their tokens — are calibrated to be cheaper than self-hosting for most use cases, foreclosing that arbitrage. And the underlying training run is reportedly being funded out of a Chinese AI ecosystem with both state and private capital flowing through it. The competitor isn't another lab; it's the entire pricing structure of frontier-grade Western inference.
What the paper itself concedes
The conclusion section is unusually self-critical for an industry blog post. DeepSeek admits the V4 architecture is "relatively complex," that the empirical techniques used to stabilize training are "not fully understood" theoretically, and that future iterations will need to "distill the architecture down to its most essential designs." The roadmap explicitly lists multimodal capabilities as still missing — V4 is a text-only model — and points to "more sparse embedding modules" as the next efficiency frontier.
There are also benchmarks where V4 simply loses. Claude Opus 4.5 beats V4-Pro 52% to 45.9% on complex multi-turn writing instructions (DeepSeek's own evaluation). Long-context retrieval at 1M tokens trails Claude Opus 4.6 by nine percentage points. On the harder reasoning benchmarks like Apex, the gap to GPT-5.4 and Gemini-3.1-Pro is wide enough that "3 to 6 months behind" is generous. None of this is in the press release; all of it is in the paper.
What it means
One year and three months on from R1, the "DeepSeek moment" has become an annual ritual. Markets did not move in a meaningful way on April 24 — NVIDIA's stock barely twitched — because the headline that "Chinese AI is competitive and cheap" has been priced in since January 2025. The under-priced risk is the second-order story: that the Chinese AI stack is now end-to-end domestic, that the open-source pricing pressure on closed-source incumbents is structural rather than one-off, and that V4 is best understood not as a model release but as a public test of whether export controls produced the outcome they were designed to prevent.
The paper itself, once you strip away the geopolitics, is a serious piece of engineering. The benchmarks are honestly disclosed, including the gaps. The architecture innovations are documented in enough mathematical detail that other labs will reproduce them within months. The pricing is aggressive but legible. And on page 16, in 13 words, a Chinese research group has confirmed in print what the AI infrastructure community has been quietly modeling all year: the dependency on NVIDIA is no longer one-way.
Written by
Veronica Salvador
Veronica Salvador is an editor at AI News Home, where she covers enterprise AI, emerging models, and the business impact of artificial intelligence. She recently completed UT Austin's Post Graduate Program in Generative AI for Business.
View all articles →This article was written by the AI News Home editorial team with the assistance of AI-powered research and drafting tools. All analysis, conclusions, and editorial decisions were made by human editors. Read our Editorial Guidelines
References
- 1.
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence — DeepSeek-AI, DeepSeek, April 24, 2026
Primary - 2.
- 3.
- 4.
- 5.
DeepSeek V4 — almost on the frontier, a fraction of the price — Simon Willison, Simon Willison's Weblog, April 24, 2026
- 6.
DeepSeek Unveils V4 at Rock-Bottom Prices With Full Support From Huawei Chips, AI Tool Insight, April 24, 2026
- 7.
DeepSeek Unveils Newest Flagship AI Model a Year after Upending Silicon Valley, Bloomberg, April 24, 2026
- 8.
China's DeepSeek releases preview of long-awaited V4 model as AI race intensifies, CNBC, April 24, 2026
Was this useful?